Key Takeaways
GEO teams should treat ChatGPT as the scale baseline and treat Claude, Perplexity, Gemini, Copilot, and Grok as separate opportunity rows. The public benchmark in the Goodie table does not prove every brand should invest equally in every platform. It does show that platform traffic and outbound referral behavior do not move in a straight line.- ChatGPT still owns the largest visible baseline. In the Goodie table, ChatGPT has 64.4% of measured platform visits from January to April 2026 and 60.8% of recent normalized referral share.
- Claude is the clearest referral-efficiency outlier in the table: 1.29% platform visit share, but 18.0% normalized referral share.
- Perplexity is smaller in total volume, with 1.85% platform visit share, but its 7.1% referral share suggests a stronger source-click or research pattern than raw visits imply.
- Gemini is not the same kind of opportunity. It has large platform usage at 29.0% visit share, but only 10.3% referral share in the table. That makes it a scale-and-growth watchlist item, not automatically a high-referral-efficiency channel.
- Copilot and Grok should remain in the dashboard, but with different labels. Copilot has a measurable 3.9% referral share in the table while platform visits were not measured. Grok had 3.5% visit share and about 0% referral share.
- Measurement must separate three signals: platform visits, AI referral clicks, and AI-influenced demand. Google’s generative AI optimization guide and Search generative AI control documentation make the caveat important: some AI exposure lives inside Google Search reporting, not a clean referrer row.
Why ChatGPT Alone Is Not Enough For GEO
ChatGPT is still the first platform most teams should measure, but it is not the whole GEO market. A ChatGPT-only report tells you where the largest visible AI source is sending traffic. It does not tell you whether smaller platforms are stronger for research, comparison, supplier discovery, technical validation, or late-stage purchase questions. The Goodie table makes the reason visible. ChatGPT’s visit share and referral share are close: 64.4% versus 60.8%. Claude and Perplexity are different. Their visit shares are tiny, but their referral shares are much larger. That mismatch is exactly what a GEO team wants to find, because a smaller source can be worth work if it sends users who are checking sources, comparing options, or validating a recommendation.| Platform group | What it is good for in a GEO report | What not to assume |
|---|---|---|
| ChatGPT | Scale baseline, brand recall, broad answer coverage, cited pages from high-volume prompts | That it captures every AI-influenced visit |
| Claude | Research and explanation-heavy prompts, B2B-style evaluation, high referral share relative to visits in the Goodie table | That direct volume will be large enough for every site |
| Perplexity | Source-led research, comparison journeys, pages users click to verify details | That growth is guaranteed in every region or category |
| Gemini | Growth watchlist, Google ecosystem behavior, possible spillover through Search | That visit share will become clean referral traffic |
| Copilot | Work-context discovery and professional workflows | That platform visits can be benchmarked cleanly from the table |
| Grok | Awareness watchlist where audience fit exists | That platform usage alone means outbound traffic |
What The Goodie Table Actually Shows
The table is not saying Claude or Perplexity are bigger than ChatGPT. It is saying platform usage and referral output are different behaviors. ChatGPT has the largest total use and the largest referral share. Claude and Perplexity have limited platform visits but disproportionately high normalized referral share, which makes them good candidates for deeper GEO testing.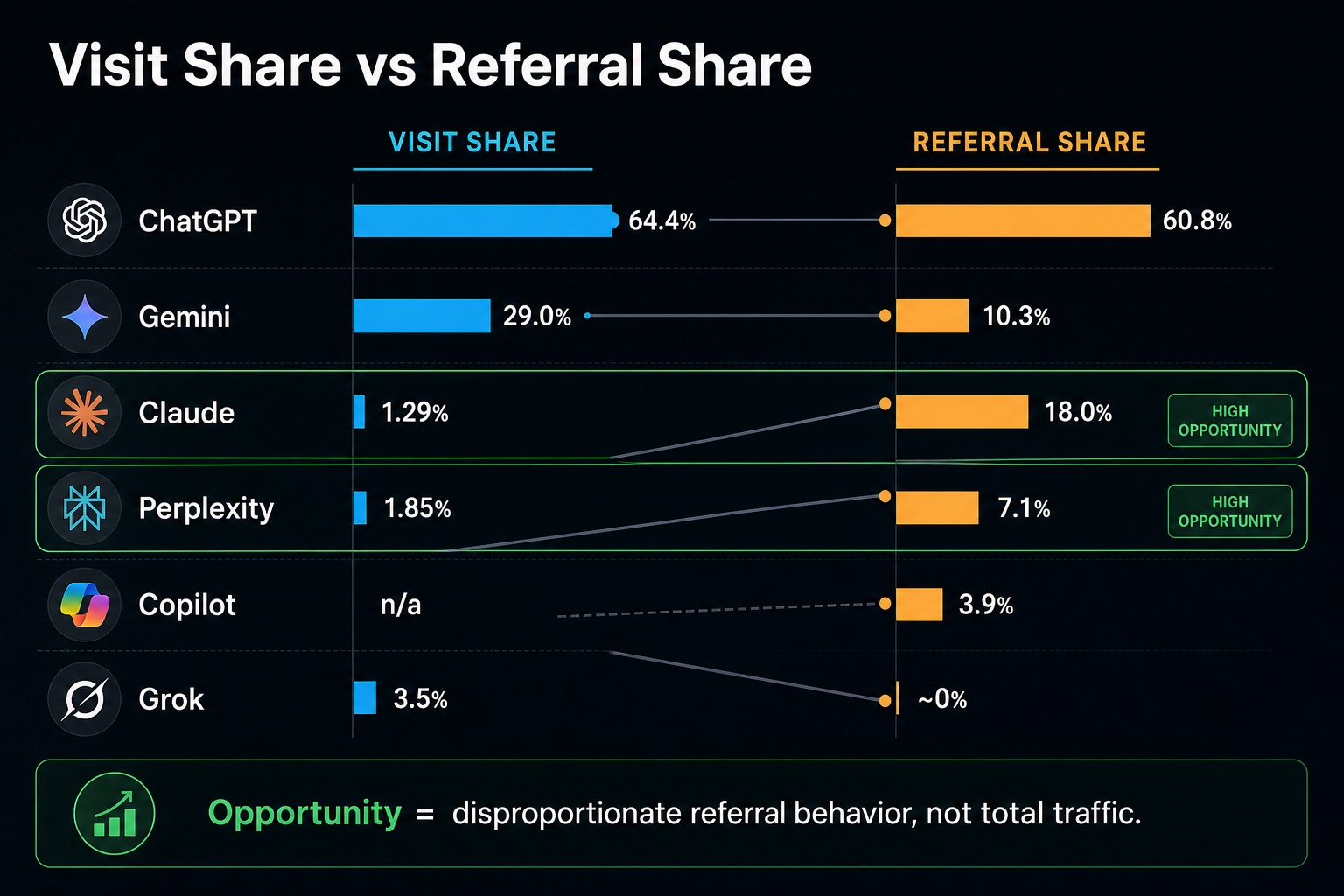
| Platform | Total visits Jan-Apr 2026 | Visit share | Recent normalized referral share | GEO interpretation |
|---|---|---|---|---|
| ChatGPT | 16.59B | 64.4% | 60.8% | Scale baseline; keep measuring, but do not stop there |
| Gemini | 7.47B | 29.0% | 10.3% | Large platform use; referral behavior is weaker than visit share |
| Grok | 904M | 3.5% | about 0% | Watch only when audience fit is clear |
| Perplexity | 476M | 1.85% | 7.1% | Small reach, stronger source-click signal |
| Claude | 333M | 1.29% | 18.0% | Strongest referral-share overperformance in the table |
| Copilot | Not measured | n/a | 3.9% | Keep as a separate row; do not bury under “other” |
Where Claude And Perplexity Create Opportunity
Claude and Perplexity create opportunity when the buyer needs evidence. These platforms are not a replacement for ChatGPT scale. They are more interesting for prompts where the user wants sources, comparisons, explanations, and confidence before taking the next step. That is why their referral share can be more important than their total platform share. In the Goodie table, Claude has 1.29% visit share and 18.0% referral share. Perplexity has 1.85% visit share and 7.1% referral share. Those numbers should trigger a test, not a budget shift by themselves.| Opportunity signal | Claude | Perplexity | What to test next |
|---|---|---|---|
| Referral share above visit share | Very strong in the Goodie table | Strong in the Goodie table | Track source clicks from comparison and research prompts |
| Research workflow fit | Strong for explanation, evaluation, and B2B questions | Strong for source-led answers and verification | Build pages that answer “why this option” and “how to compare” |
| Total volume | Still limited | Still limited | Use conversion quality, not raw sessions, to decide priority |
| Best content candidates | Method pages, comparison pages, evidence-backed guides, case-style explainers | Source-rich guides, product/category comparisons, data pages, FAQ hubs | Record cited URLs and update pages that are already close |
| Main caveat | High referral share may not repeat in every vertical | SE Ranking reports regional and time-based volatility in AI traffic share | Re-test monthly and compare by category |
How Gemini, Copilot, And Grok Fit Into The Watchlist
Gemini, Copilot, and Grok should stay in the dashboard, but they need different labels. Gemini is a growth-and-scale watchlist item. Copilot is a professional workflow watchlist item. Grok is an audience-fit watchlist item. None of them should be hidden inside “other AI,” because early changes are easy to miss once reporting is aggregated. SE Ranking’s 2026 AI traffic research says Gemini grew quickly from a small base, and its separate Gemini-versus-ChatGPT analysis reports that Gemini overtook Perplexity by its measurement in early 2026. That does not mean Gemini sends better visitors today. It means the platform is large enough and connected enough to Google’s ecosystem that GEO teams should watch it separately.| Platform | Dashboard label | Main question | Practical test |
|---|---|---|---|
| Gemini | Growth and Search-adjacent watchlist | Are Gemini and Google AI surfaces changing brand discovery? | Compare prompt visibility with Search Console changes and organic landing pages |
| Copilot | Work-context watchlist | Does the audience use Microsoft workflows for research? | Test procurement, B2B, documentation, and how-to prompts |
| Grok | Audience-fit watchlist | Does the category’s audience overlap with Grok’s active users? | Track only if prompts show mentions, citations, or competitor presence |
How To Research GEO Beyond ChatGPT
Researching GEO beyond ChatGPT is a monthly measurement habit, not a one-time article rewrite. The goal is to find where non-ChatGPT platforms mention the brand, cite the site, send visible referral traffic, or influence follow-up demand. The workflow should be small enough to repeat and structured enough to compare month over month. Use this workflow:- Pick 3-5 priority categories or buyer questions.
- Write 10-20 prompts per category. Include discovery prompts, comparison prompts, risk prompts, and “what should I check before buying” prompts.
- Run the prompts in ChatGPT, Claude, Perplexity, Gemini, and Copilot. Add Grok only where audience fit is real.
- Record brand mention, rank/order of mention, cited URLs, competitor URLs, answer framing, and whether the answer includes source links.
- Match visible referrers in analytics to the same time window. Use normalized platform names such as ChatGPT, Perplexity, Gemini, Claude, Copilot.
- Add business quality metrics where available: leads, trial starts, orders, GMV, pipeline, revenue per visit, or qualified lead rate.
- Re-test the same prompt set monthly, then add or remove prompts based on category changes.
| Field | Why it matters |
|---|---|
| Platform | Prevents non-ChatGPT movement from being hidden |
| Prompt group | Separates discovery, comparison, and purchase-intent behavior |
| Brand mentioned | Measures answer visibility |
| URL cited | Shows which page is trusted enough to support the answer |
| Competitor cited | Reveals citation gaps and page types to study |
| Visible referral | Connects AI answer behavior to analytics |
| Business outcome | Prevents teams from optimizing only for visits |
| Attribution note | Keeps direct, organic, and AI-influenced demand separate |
What Content Gets Recommended By Research-Heavy Platforms
Research-heavy platforms are more likely to reward pages that help users verify a choice. That usually means comparison tables, evidence-backed guides, category explainers, data pages, policy pages, and detailed product or solution pages. Thin brand pages can still appear for navigational questions, but they rarely satisfy comparison or validation prompts. The content goal is not to write for one AI bot. It is to create pages that a retrieval system can understand and a cautious user can trust. Google’s official AI optimization guidance points back to core Search quality, crawlability, helpful content, and clear media. The same discipline helps answer engines because they need concise claims, sourceable facts, and page structure.| Prompt intent | Page type that can win | What the page needs |
|---|---|---|
| “What is the best option for X?” | Comparison guide | Selection criteria, table, caveats, who each option fits |
| “How do I choose X?” | Buyer guide or category guide | Step-by-step decision rules, definitions, examples |
| “Is X safe / reliable / compliant?” | Evidence or policy page | Source-backed statements, dates, certifications, limits |
| “Compare A vs B for Y” | Use-case comparison page | Clear tradeoffs, not just feature lists |
| “What should I check before buying X?” | Checklist page | Practical checks, warning signs, next actions |
| “Where can I find specs or requirements?” | Product/detail page | Structured specs, FAQs, images, downloadable evidence if useful |
Common Measurement Mistakes And Attribution Limits
The most common mistake is to treat non-ChatGPT GEO as a traffic-volume race. That misses the point. The opportunity often shows up as disproportionate referral share, higher-intent sessions, new cited URLs, or assisted demand that later appears as direct, organic, or branded search. Measurement must be cautious enough to avoid false precision.| Mistake | Why it causes bad decisions | Better rule |
|---|---|---|
| Ranking platforms only by total visits | Smaller platforms with stronger research behavior disappear | Compare visit share, referral share, citation rate, and outcome |
| Treating referral share as revenue share | Referral behavior does not guarantee conversion | Add order rate, qualified lead rate, GMV, or pipeline quality |
| Hiding all non-ChatGPT platforms under “other” | Early signals are averaged away | Keep separate rows for Claude, Perplexity, Gemini, Copilot, and Grok |
| Assuming Google AI sends a clean referrer | Google AI features live inside Search systems | Pair analytics with Search Console and prompt tests |
| Rewriting pages before prompt testing | The team may fix pages AI systems never consider | Test prompts, record cited URLs, then optimize |
| Treating one benchmark as universal | Platform behavior varies by category, region, and user task | Use public data as a hypothesis, then test your own site |