短答案:如果“有效”指让 ChatGPT、Perplexity、Gemini 或 Google AI 功能更常引用你的网站,当前公开证据不支持这个说法。llms.txt 不是骗局,它是一个社区提出的 Markdown 导航文件,原本更适合给 AI 工具提供按需上下文。但到 2026 年 5 月,可复核研究和平台文档都没有证明它能带来稳定的 AI 引用提升。更稳的做法是:保留它作为低成本辅助文件,把主要精力放在可抓取 HTML、可信来源、答案块、内部链接和固定 prompt 复测上。
Last updated: 2026-05-14
视频摘要: 这段视频把本文结论压缩成三步:先看证据,确认 llms.txt 暂无可测量引用提升;再看平台文档,确认主要系统仍然围绕 robots.txt、可索引页面和普通搜索信号工作;最后把执行预算转向可抓取正文、证据源、答案块和 prompt 复测。
先判案:它不是诈骗,但不是增长杠杆
llms.txt 现在最容易被误卖成“AI 搜索排名按钮”。这个说法站不住。更准确的判断是:llms.txt 是一个低风险、低优先级、未来可能有用的辅助文件。它可以帮助技术文档用户复制上下文,也可以表达你希望 AI 工具优先阅读哪些页面,但它不能替代索引、内容质量、来源可信度和真实用户需求。
把这件事说清楚很重要,因为很多团队的时间预算并不大。如果你只有半天做 AI 搜索优化,先做 llms.txt 通常不是最划算的动作。你更应该检查 AI 爬虫 robots.txt 策略、页面是否能被匿名访问、正文是否有可引用答案块、关键事实是否有来源、以及品牌在 AI 回答中是否被正确描述。
判断一个 GEO 动作是否值得投入,要看三件事:有没有平台确认,能不能在日志或搜索数据里观察到,是否能改变用户看到的答案。llms.txt 在这三项里都还很弱。它可以存在,但不该成为团队周报里的核心胜利项。
证据台:目前公开资料指向同一个结论
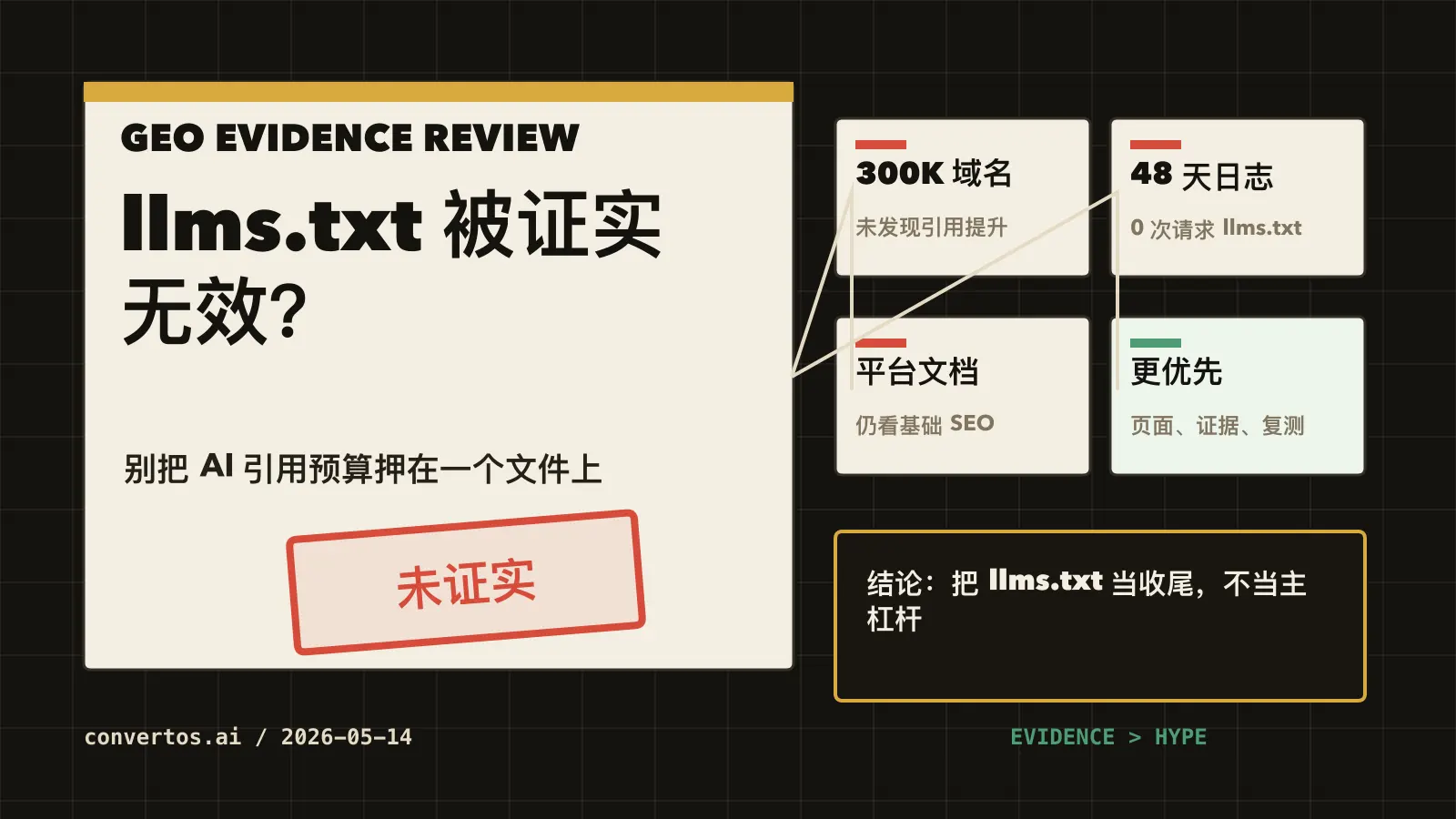
公开证据的方向很一致:llms.txt 暂时没有证明能提升 AI 引用。这里的关键词是“证明”。不是说它永远无效,也不是说所有行业都不该放,而是说没有足够证据支持把它当作优先级最高的 GEO 动作。
| 证据 | 观察对象 | 发现 | 怎么解读 |
|---|---|---|---|
| SE Ranking 的 300,000 域名研究 | 近 30 万个域名、llms.txt 是否存在、AI 引用频率 | 只有 10.13% 域名有 llms.txt;统计分析和 XGBoost 模型都没有发现它提升引用频率 | 这是强宏观证据:文件存在本身不是 AI 引用驱动因素 |
| WISLR 的 48 天服务器日志分析 | 71,603 次总请求,其中 12,099 次 AI/爬虫请求 | 48 天内没有 AI bot 请求 /llms.txt 或 /llm.txt |
单站样本不能代表全网,但它说明真实日志里可以直接验证这个问题 |
| Google AI features 文档 | Google AI Overviews 和 AI Mode 的站长指南 | Google 说 AI 功能沿用基础 SEO 要求,并明确不需要新机器可读文件或特殊 AI markup | 对 Google AI 搜索来说,llms.txt 不是公开要求 |
| OpenAI 爬虫文档 与 Anthropic 爬虫说明 | OAI-SearchBot、GPTBot、ChatGPT-User、ClaudeBot、Claude-User、Claude-SearchBot | 两家公司都把控制重点放在 user-agent、robots.txt 和请求来源上 | 平台公开机制是“允许或阻止爬取”,不是“读取 llms.txt 后决定是否引用” |
| Search Engine Roundtable 对 John Mueller 发言的记录 | Google Search 代表对 llms.txt 的公开回应 | John Mueller 在 2025 年 6 月表示当时没有 AI 系统使用 llms.txt,并提醒看服务器日志 | 这是平台人员评论,不等于永久政策,但可作为谨慎信号 |
这张表的重点不是“谁赢了辩论”,而是帮你决定预算。大样本研究没有发现引用提升,日志样本没有看到 AI bot 请求,主流平台文档没有把它列成 AI 搜索条件。此时继续把它包装成“必做项”,就有点像拿一张便签当增长策略。
原始设计:它主要是给 AI 工具看的上下文文件
llms.txt 的原始设想并不是“排名信号”。llms.txt 提案由 Jeremy Howard 在 2024 年 9 月发布,核心是把网站的重要信息整理成一个 Markdown 文件,让 LLM 在用户请求帮助时更容易找到合适上下文。提案也说得很清楚:它更可能在推理或按需读取时有用,而不是作为训练阶段的主要信号。
这就解释了为什么 SEO 圈会误读它。它长得像 robots.txt,也放在网站根目录,于是很多人自然把它想象成“AI 版 robots.txt”。但两者目的不同。Google 的 robots.txt 文档把 robots.txt 定义为控制爬虫可以请求哪些 URL 的文件;llms.txt 更像给 AI 工具的一张精简目录。一个是访问控制,一个是上下文整理。
如果你运营的是开发者文档、API 文档或复杂产品说明,llms.txt 仍然有用。比如用户在 Claude、ChatGPT 或 Cursor 里问“如何接入这个 SDK”,他们可能主动提供你的 llms.txt 或 llms-full.txt,让模型少读导航、广告和脚本。这个场景是用户体验,不是 AI 搜索引用提升。
为什么它当不了 GEO 快捷键
llms.txt 当不了 GEO 快捷键,主要有四个原因。第一,主流平台没有公开承诺把它作为引用、排名或回答选择信号。第二,大量实现只是 URL 列表,和 sitemap 信息高度重复。第三,AI 搜索引用更依赖页面是否能被发现、索引、理解和信任,而不是某个孤立文件。第四,团队很容易因为它“看起来技术化”而忽略真正难做的内容和证据工作。
拿一个 B2B SaaS 页面举例。你在根目录放了一个 llms.txt,里面列出“首页、定价页、博客页、关于我们”。这对 AI 系统的帮助很有限,因为它没有回答真实问题:你服务谁,产品解决什么问题,证据在哪里,和竞品有什么区别,哪些页面能支持这些事实。如果页面正文仍然含糊,AI 即使看见目录,也未必会引用你。
GEO 的核心不是“给模型一张地图”,而是让每个候选页面本身足够清楚。你需要的是 AI 搜索可引用内容:直接答案、定义块、表格、来源、FAQ、视频摘要和可复测指标。llms.txt 只能指向这些内容,不能替这些内容承担可信度。
什么时候仍然值得加一个 llms.txt
llms.txt 不是优先事项,但也不是禁区。如果你的站点有清晰的信息架构,加一个简短、准确、不夸张的文件成本很低。关键是别把它写成关键词堆叠,也别把它当成 blocking 或授权机制。
适合加的情况有三类。第一,开发者文档、API 文档、开源工具、复杂教程,用户可能把文档交给 AI 工具阅读。第二,你已经完成了基础 SEO、结构化内容、内部链接和核心页面改写,llms.txt 只是收尾。第三,你想为未来可能出现的平台支持保留一个干净入口。
不适合优先做的情况也很明确。网站还没有稳定 sitemap,关键页面被 CDN 或登录墙挡住,产品定义互相矛盾,文章正文没有来源,或者还没有固定的 AI 可见度测试问题集。这些问题不修,llms.txt 只能让团队产生“我们已经做过 AI SEO 了”的错觉。
同样半天时间,应该先做什么?
如果你只有 3 到 4 小时,不要先围着 llms.txt 打转。先做能被平台文档、日志和页面质量共同支持的动作。下面这张表可以直接当成优先级清单。
| 优先级 | 选项 / 动作 | 证据:为什么比 llms.txt 更值得先做 | 成功信号 |
|---|---|---|---|
| P0 | 确认关键页面允许抓取和索引 | Google AI 功能、OpenAI Search 和 Claude Search 都依赖可访问内容 | 页面返回 200,未 noindex,robots/CDN 没误拦 |
| P0 | 给核心页面补 40 到 90 字答案块 | AI 回答更容易摘取清晰段落 | 每个主要 H2 单独拿出来也能回答问题 |
| P1 | 给事实和判断补来源 | 引用系统更偏好可复核内容 | 重要声明旁边有官方文档、研究、案例或方法说明 |
| P1 | 建立固定 prompt 测试集 | 没有复测就无法判断是否真的进步 | 每月同一批问题记录提及、引用和错误 |
| P1 | 修内部链接和专题集群 | 让搜索系统更容易理解页面关系 | 相关文章互相指向,锚文本自然,不堆裸 URL |
| P2 | 记录 AI bot 服务器日志 | 判断爬虫有没有访问、访问了什么 | 能看到 OAI-SearchBot、Claude-SearchBot、PerplexityBot 等请求 |
| P3 | 加简洁 llms.txt | 为未来和文档型使用场景预留入口 | 文件准确、短、无关键词堆叠,能被手动使用 |
这个顺序有点不性感,但有效。GEO 很多时候不是多一个神秘文件,而是把页面从“人勉强能懂”改成“人和机器都能复核”。如果你还没做过基线测试,可以先跑一次 GEO 审计,用固定问题集看品牌是否被提到、是否被正确描述、引用来自哪里。
7 天替代计划:把“文件崇拜”改成可复测系统
第一天,选 10 个最重要的页面。不要选全站,先选有商业价值的产品页、方案页、教程页和案例页。记录每个页面的 URL、目标问题、核心转化动作和当前索引状态。
第二天,写 30 个 prompt。分成品牌、品类、问题、竞品、购买和实施六组。每组至少 5 个问题。用同一批问题在 ChatGPT、Perplexity、Gemini、Claude 或你团队关心的平台里做基线记录。
第三天,修页面开头和 H2 开头。每个页面必须在首屏回答一个清楚问题,每个主要 H2 开头放一个短答案。不要写“在当今数字环境中”,直接说结论。
第四天,补证据。平台行为用官方文档,行业判断用公开研究或方法说明,产品能力用真实页面和案例。没有证据的夸张句直接删掉。
第五天,补结构模块。每个重点页面至少有一个表格、一个 checklist、一个 FAQ 或一个视频摘要。结构模块的目标不是“丰富”,而是让读者和 AI 都能快速抓住判断条件。
第六天,检查技术访问。看 robots.txt、canonical、noindex、服务器状态、CDN 规则、渲染后 HTML 和 sitemap。这里可以顺手加 llms.txt,但只作为最后一步。
第七天,复测同一批 prompt。不要只看“有没有提到”。记录是否引用、引用哪个 URL、答案是否正确、竞品是否出现、下一步行动是否指向你能承接的页面。这才是能进入周报的 GEO 数据。
决策卡:你现在要不要做 llms.txt?
下面这张卡可以帮助团队快速决策。分数越高,越适合把 llms.txt 放进本周任务;分数越低,就先别碰它。
| 问题 | 是 | 否 |
|---|---|---|
| 关键页面已经能被抓取、索引,并且不是纯 JS 承载正文 | +2 | -3 |
| 已经有稳定 sitemap 和干净内部链接 | +1 | -2 |
| 页面里有答案块、来源、FAQ 和可引用表格 | +2 | -3 |
| 你的站点是开发者文档、API 文档或复杂教程型站点 | +2 | 0 |
| 团队已经有 AI prompt 基线和月度复测表 | +2 | -2 |
| 你准备把 llms.txt 当成“AI 引用提升保证”向老板汇报 | -4 | +1 |
总分 5 分以上,可以做,但只当辅助。0 到 4 分,先做页面和复测。0 分以下,暂时别做,因为你更大的问题不是缺少 llms.txt,而是缺少可被引用的内容资产。
FAQ
来源信号:SERP 问题信号、相关问题、社区讨论、平台文档和行业文章标题中反复出现的问法,已合并成适合读者理解的版本。
llms.txt 会提高 ChatGPT 或 Perplexity 引用率吗?
目前没有可靠证据证明会。SE Ranking 的大样本研究没有发现引用频率提升,WISLR 的日志样本也没有看到 AI bot 请求该文件。把它当成可测试辅助项可以,把它当成引用保证不行。
Google AI Overviews 或 AI Mode 需要 llms.txt 吗?
不需要。Google 的 AI features 文档说,AI Overviews 和 AI Mode 仍然沿用基础 SEO 要求,并明确不需要新的机器可读文件或特殊 AI markup。先保证页面可索引、正文可读、内容可靠。
llms.txt 和 robots.txt 是一回事吗?
不是。robots 文件控制爬虫访问;llms 文件更像给 AI 上下文用的精选阅读目录。
如果成本很低,为什么不直接加?
可以加,但不要让它挤占更重要的工作。低成本不等于高优先级。一个 15 分钟文件不该替代 3 小时的页面修复、来源补充和 prompt 基线。
Convertos.ai 应该怎么处理 llms.txt?
建议保留一个简洁版本,列出产品定位、核心页面、GEO 教程、SEO 教程和工具入口。但周报里不要把它写成成果主项,主项应该是 AI 引用基线、页面修复、日志访问和复测结果。
下一步
把 llms.txt 放到正确位置:它是收尾,不是开局。今天最值得做的不是再找一个生成器,而是选 10 个页面,跑一次 AI 可见度基线,修掉最明显的页面问题,再用同一批 prompt 复测。
如果团队需要一个起点,可以先看 答案块写作与引用抓取,再配合 AI 爬虫 robots.txt 策略。这两件事通常比 llms.txt 更接近 AI 引用的真实前置条件。
内容声明
本文最后复核于 2026-05-14,参考了 llms.txt 原始提案、Google Search Central、OpenAI 与 Anthropic 爬虫文档、SE Ranking 的公开研究、WISLR 的服务器日志分析,以及行业公开讨论。平台行为会变化,本文结论应理解为“截至当前公开证据,llms.txt 不是已证实的 AI 引用增长杠杆”。发布后建议每季度复查一次官方文档和站点服务器日志。